
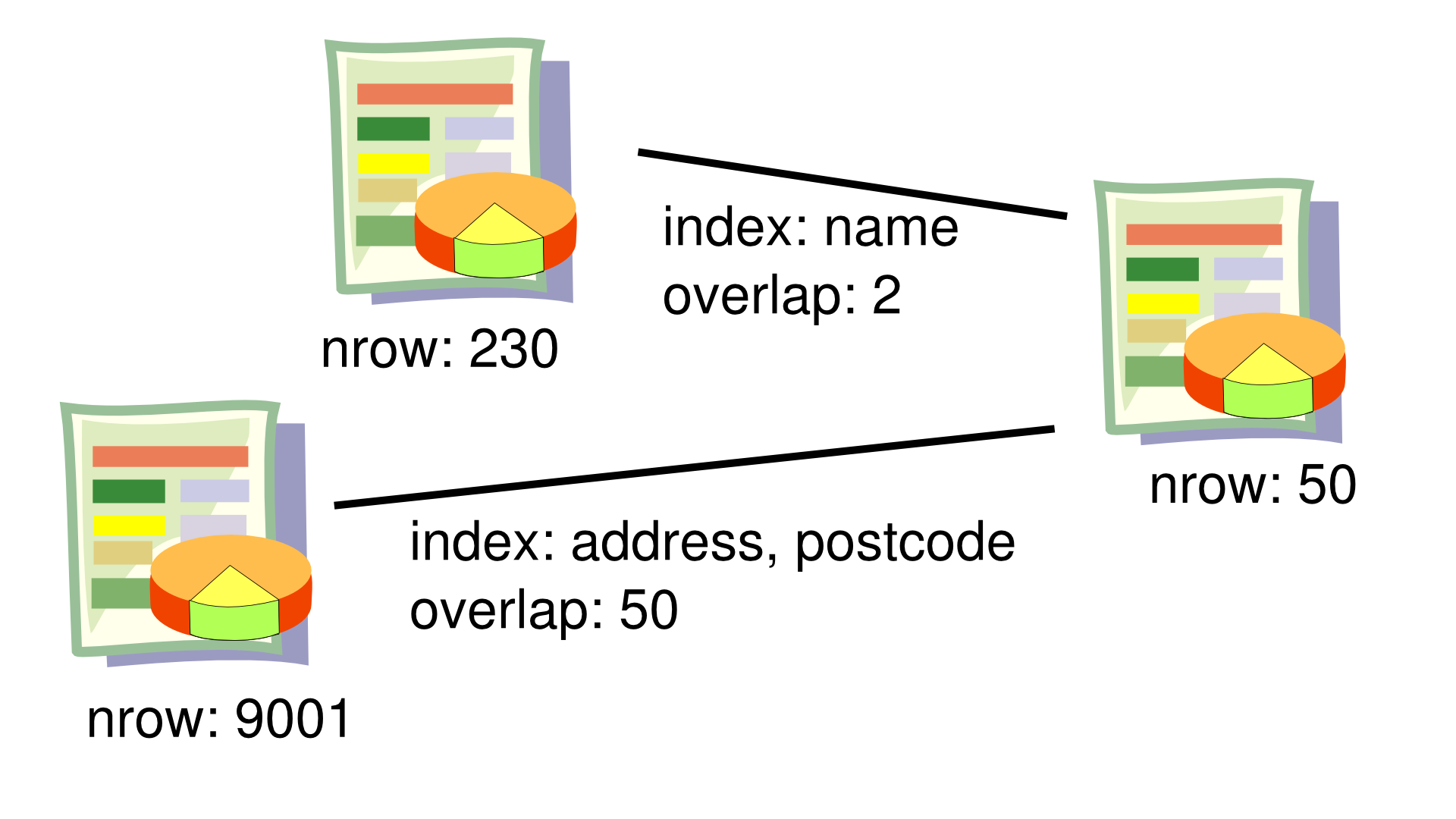
I stumbled across a very interesting post on pagerank for spreadsheets. The post is a summary of a talk, but provided an interesting look at trying to understand open data at scale. Something I've tried doing several times, including my Adopt A Federal Government Dataset work. Which reminds me of how horribly out of data it all is.
There is a shitload of data stored in Microsoft Excel, Google Spreadsheet and CSV files, and trying to understand where this data is, and what is contained in these little data stores is really hard. This post doesn’t provide the answers, but gives a very interesting look into what goes into trying to understand open data at scale.
The author acknowledges something I find fascinating, that “search for spreadsheet is hard”—damn straight. He plays with different ways for quantifying the data based upon number columns, rows, content, data size and even file formats.
This type of storytelling from the trenches is very important. Every time I work to download, crunch and make sense of, or quantify open data, I try to tell the story in real-time. This way much of the mental exhaust from the process is public, potentially saving someone else some time, or helping them see it through a different lens.
Imagine if someone made the Google, but just for public spreadsheets. Wish I had a clone!