
There was a lot of fake news swirling around during the election, and like I do with other ways that technology (APIs) are impacting our world, I wanted to better understand it before I opened my mouth telling people there was or was not a problem here--let alone talk about any possible solution. Building on my friend Mike Caulfield's work, I set out to understand how "fake news" was being shared, compared to "regular news".
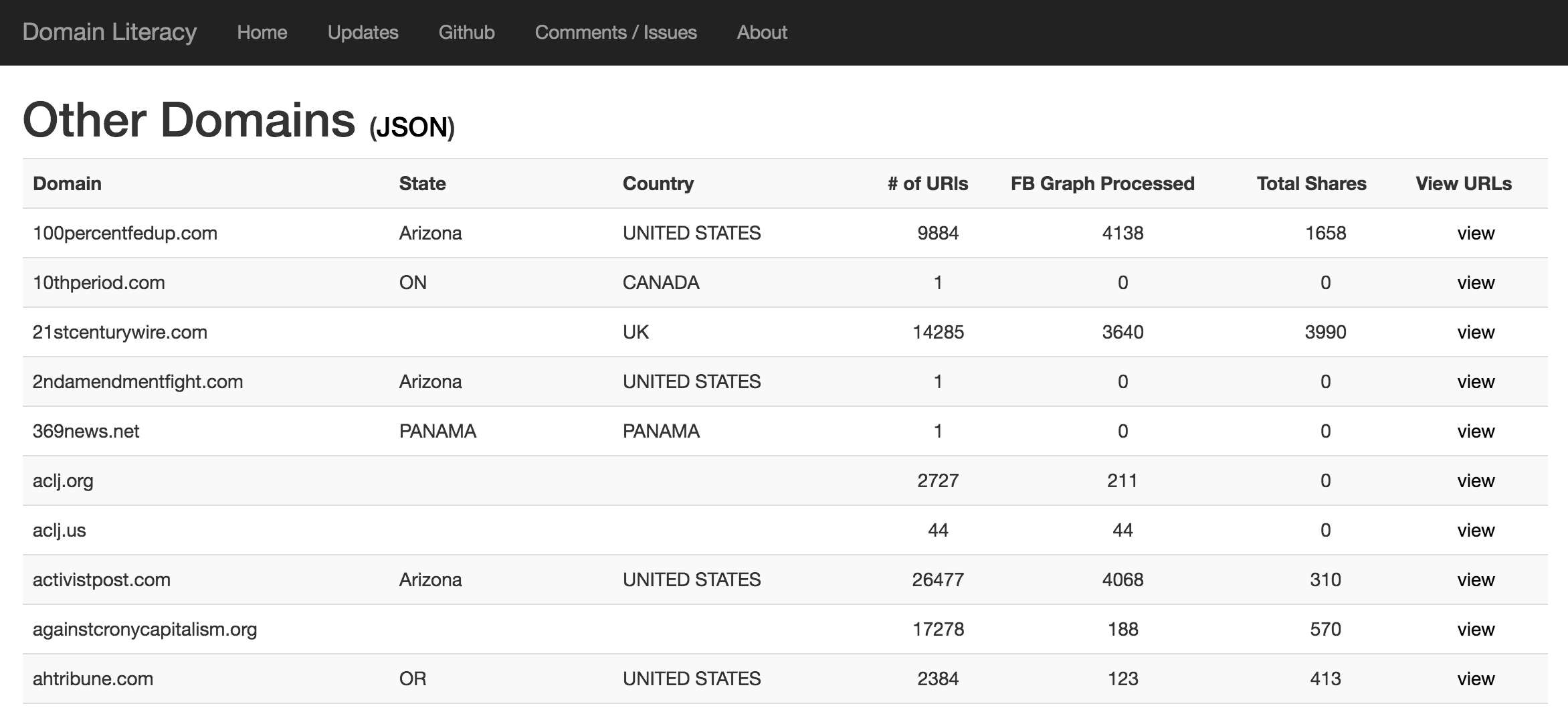
I seeded my list of "fake news" domains with just a handful that are making the rounds in the press and kept adding to it, resulting in 327 separate domains I was evaluating as of yesterday when I spun down the servers. I fired up an Amazon server and began pulling all of the URLs that make up these sites, and passing those URLs to Facebook so that I could better understand how these sites were being shared, compared to other more recognized news outlets.
Establishing a list of these domains, and harvesting their sites isn't that hard, but understanding their virality on Facebook and Twitter is more costly, as these platforms are in the business of monetizing this information, which contributes to why this is a problem in the first place. I was able to get around some of the limitations of the Facebook and Twitter APIs by launching many different servers (30 as of yesterday), that allows me to pull data with a unique IP address--something that is proving to be more costly than any value I generated.
I am shutting down the servers, and leaving my research on Github for others to build on. I am just unsure of what would be next, uneasy about spending money I do not have on this, and be in the business of generating lists of domains that say this is "good" or this is "bad". The reasoning behind these websites spreading information or disinformation vary, and honestly it is very difficult to draw a line regarding what is good or bad--something I'm not very interested in spending my time doing. I will keep working on evolving the code for this project to keep profiling domains, hopefully providing a fingerprint of healthy and unhealthy behavior.
Honestly, this world is very very toxic. These folks are obviously very scared of people of color, government, god, and much, much more, and I'm not really interested in spending my days wading through this stuff. In my opinion, there is no technological solution to this problem. We can encourage the platforms to filter better, and the advertising networks to cut off the revenue generation, but they will continue. This group of disinformation peddlers are extremely resourceful and will find new domains if they are blacklisted, leverage alternative advertising networks when they are cut-off, and launch new social media accounts when cut-off. In short, it would be technology whack-a-mole, and I'm not interested in playing.
The diversity in the number of sites I came across presented the biggest challenge, with the only common goal across them being capitalist in nature. Many sites speak to the alt-right, or right, but many were crafty at finding affinity with often left-leaning causes like herbal products, marijuana, aliens, and beyond. They are all very search engine optimization (SEO), and social media marketing (SMM) savvy. They leverage all the top social and seo services, and were obviously very adept at purchasing new domains, and scaling content generation, cross-posting, and gaming Google, Facebook, and Twitter along the way. You could dedicate your life to counteracting this world, and die having never accomplished your mission.
There is plenty of interesting work to be conducted in this area, but it is all work that will cost money to fire up servers, crunch, store, and process the data. Being an independent operation I just can't afford spending money doing this, and after spending upwards of $500.00 on computing and storage costs, I didn't see any light at the end of the tunnel. I'd be happy to continue indexing domains, or evaluating which social services and advertising network these disinformation sites are using, but I can't continue doing it without any funding assistance, I have better things to spend my time and money on, that provide a measurable impact on digital literacy.
In the end,we have to focus on a more digitally literate society. People who are willing to question who is behind any news item they share. Who individually is responsible any piece of information, as well as which company's, government agencies, and ideology exists behind anything being shared. I just do not feel like technology can get us out of this mess. It is humans and educated humans that can get us out of this quagmire. A lack of education is why people voted for Donald Trump, and it is why they believe in fake news, propaganda, and disinformation. No amount of filters, or domain black or white lists will make that better--we need people to be curious, inquisitive, and to want to understand what is behind.
I'm hoping others will continue to work on other data projects and tooling to help push back on this problem. I want all of us to push back on Facebook and Google to help provide solutions. Ultimately I do not hold out much hope because it is the advertising driven incentive model that will drive this. The clueless white dudes behind these efforts, like the guy who NPR found to be behind the Denver Guardian fake new site, are the problem...they don't care about left or right, they care about making money. This is why fake news, cybersecurity, and any other cesspool of the Internet will keep bubbling up and burning all of us--until we address this incentive model for building out the Internet, very little will change.